
Overview
The extension does its best to extract the important parts of the page. However, not all pages are structured the same way. Some pages require a custom "Parser" that can be created by entering a few CSS parameters into a "Parser" form on the extension popup.
Once a parser has been created, it generally works for all pages on the site and will automatically be used for all future visits by all users. It will also be used by any RSS agents that automatically collect articles from the site.
Creating a definition
A custom parser can be created fairly easily with some basic knowledge of CSS selectors and the ability to use the browser inspector. To get started, open the browser extension on the page you wish to create the parser for and click the orange "Parser button in the top right.
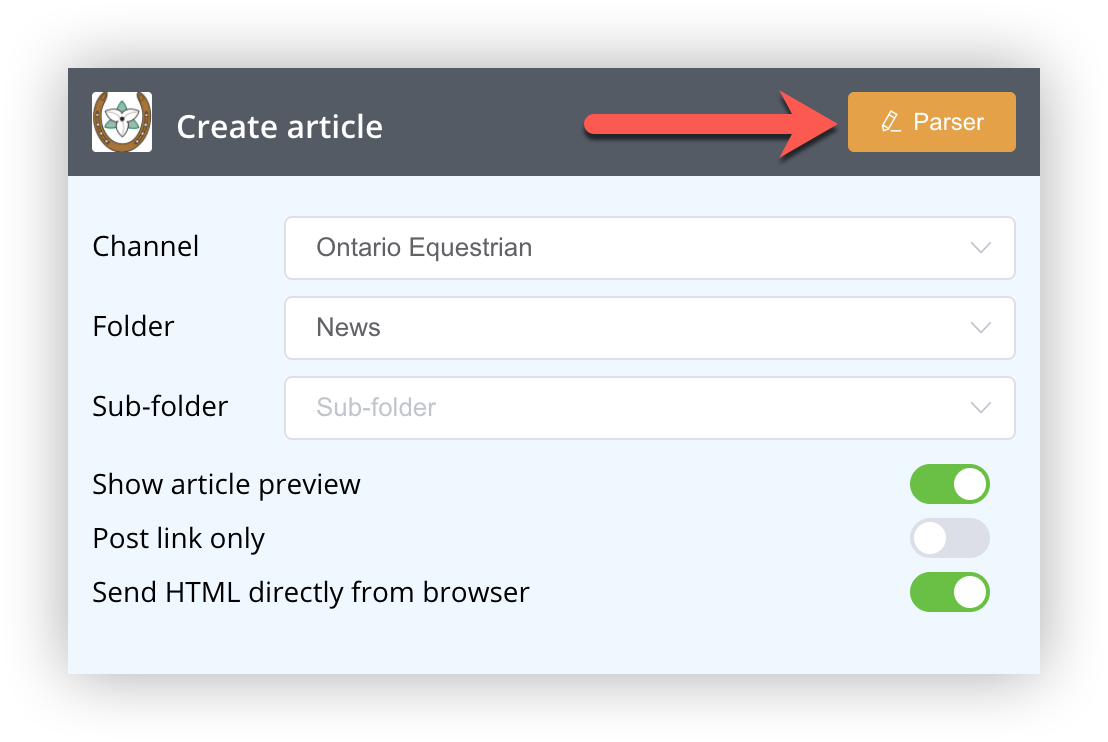
Top of form
The parser form is now displayed. The top part shows some basic information about the current parser if one is defined:
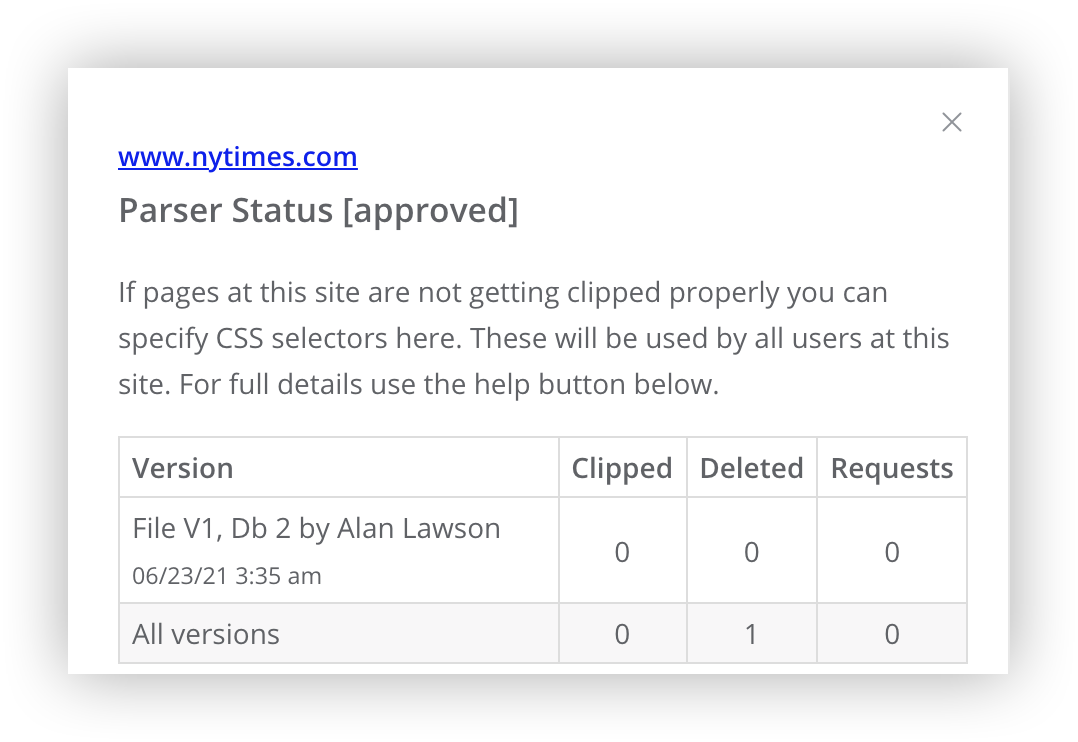
- Parser status - When creating a parser it starts out as "draft" and will only be used for your own clipping. Once you are satisfied with it, use the "Mark parser as approved" switch at the bottom of the form.
- Version - Every time changes are made to an "approved" parser a new "draft" version is created and the version number is incremented. In some cases a special file parser may have been created by Kuloo for especially complex pages in which case the file version will be listed along with the form (or Db) version number. The most recent form editor and modification timestamp also appear.
- Clipped - how many pages have been clipped from this site using this parser version as well as a total for all versions.
- Deleted - how many times have clipped articles been deleted from this site (usually because of formatting problems).
- Requests - when a clipped article is deleted, if you are unfamiliar with CSS, you can optionally make a request for Kuloo to create a custom parser. You will be notified when one has been created. The total number of requests made for the site are also displayed.
Parser fields
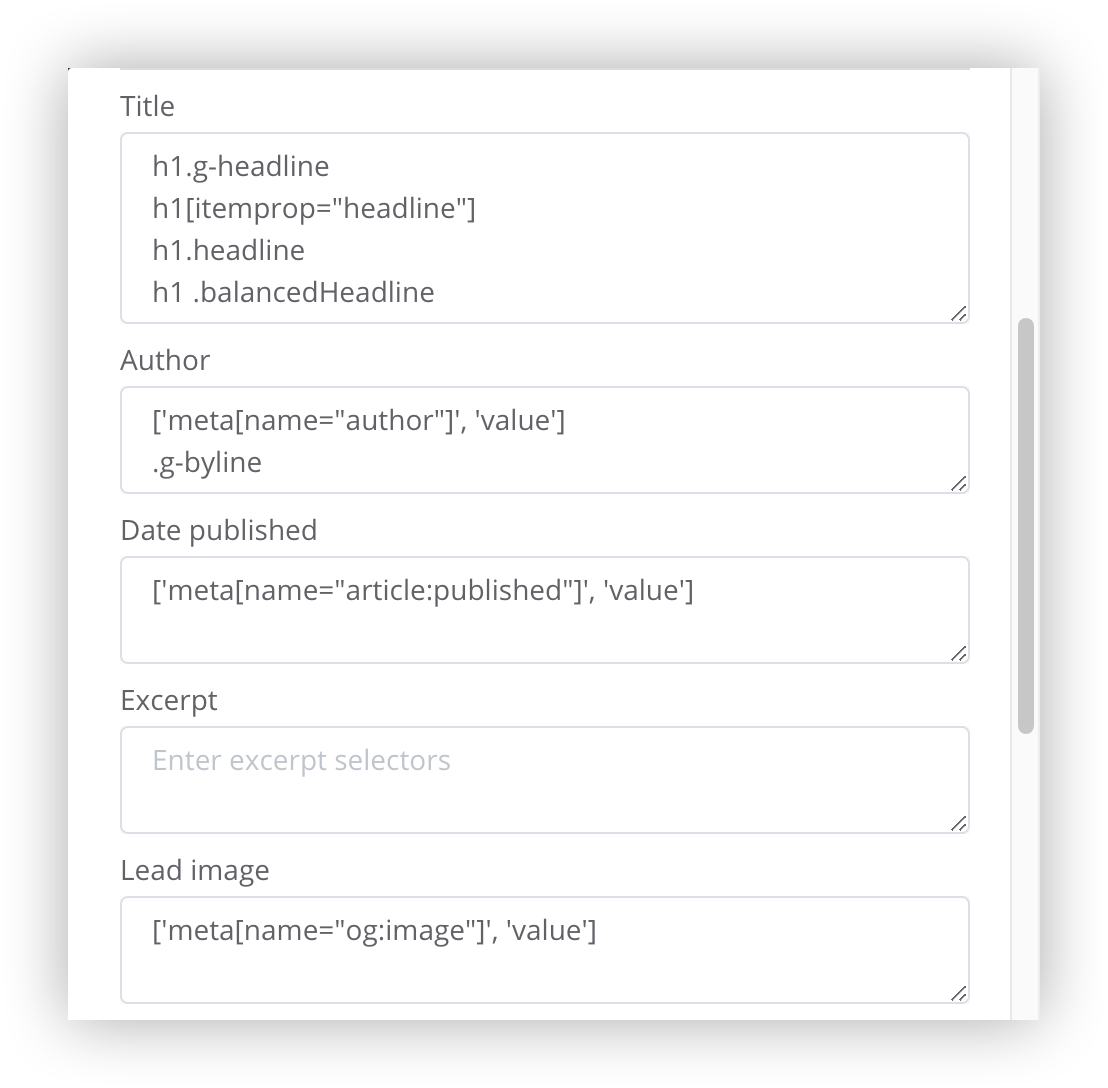
Each field can contain a list of CSS selectors to be used to extract the text from the page. Multiple selectors can be entered, one per line. If nothing matches the first selector, the second one will be tried. If nothing matches any of the selectors on the parser form then the default selectors of the engine will be tried. If still nothing matches, a blank result will be returned.
To see the actual HTML of the page, right click anywhere on the page and click "inspect". Here is a sample section of HTML:
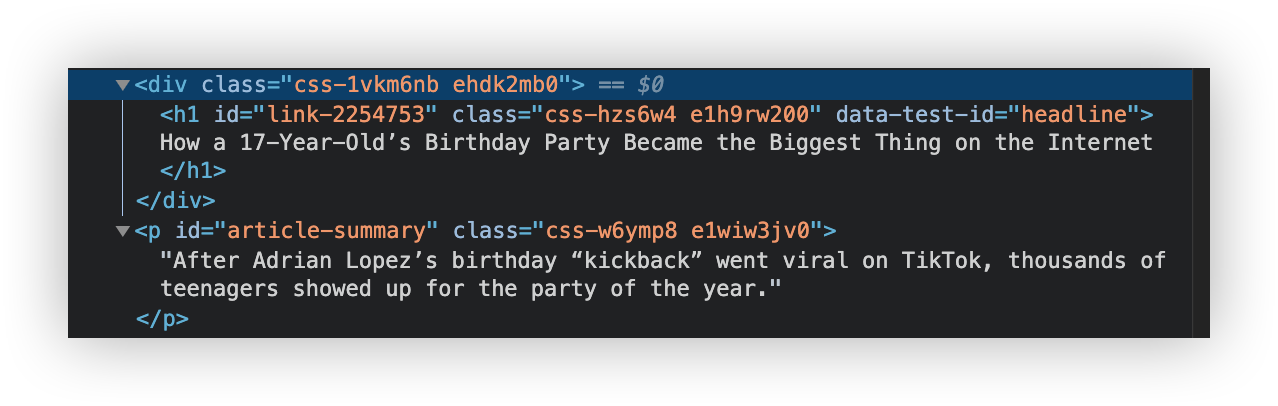
To extract the title from the above HTML the CSS selector would be:
h1[data-test-id="headline"]
To extract the excerpt field (or summary) the CSS selector would be:
p#article-summary
For a detailed explanation of CSS selectors with many examples see this article:
https://www.w3schools.com/cssref/css_selectors.asp
Special selectors from jQuery can also be used:
https://api.jquery.com/category/selectors/
More detailed explanations and examples on these parser fields can be found at the Github page:
https://github.com/postlight/mercury-parser/blob/master/src/extractors/custom/README.md
The above Github page also describes how to extract text from attributes (useful for "meta" tags) as well as how to transform text (ie. turning "IMG" tags into "Figure" tags).
Note that the examples shown in the Github page include extra quotes and commas that are required for use in JavaScript code. They are not needed in the simplified formatting used here.
Lead image - The default Mercury parser behaviour has been overridden for this field. Normally if a selector is defined but no match is found, Mercury will use a default selector. This has been overridden so that if no image is found using the defined selectors, the default will not be used and no image will be returned.
Special fields
There are three fields that are handled slightly differently. The content, transforms, and clean fields each have special handling.
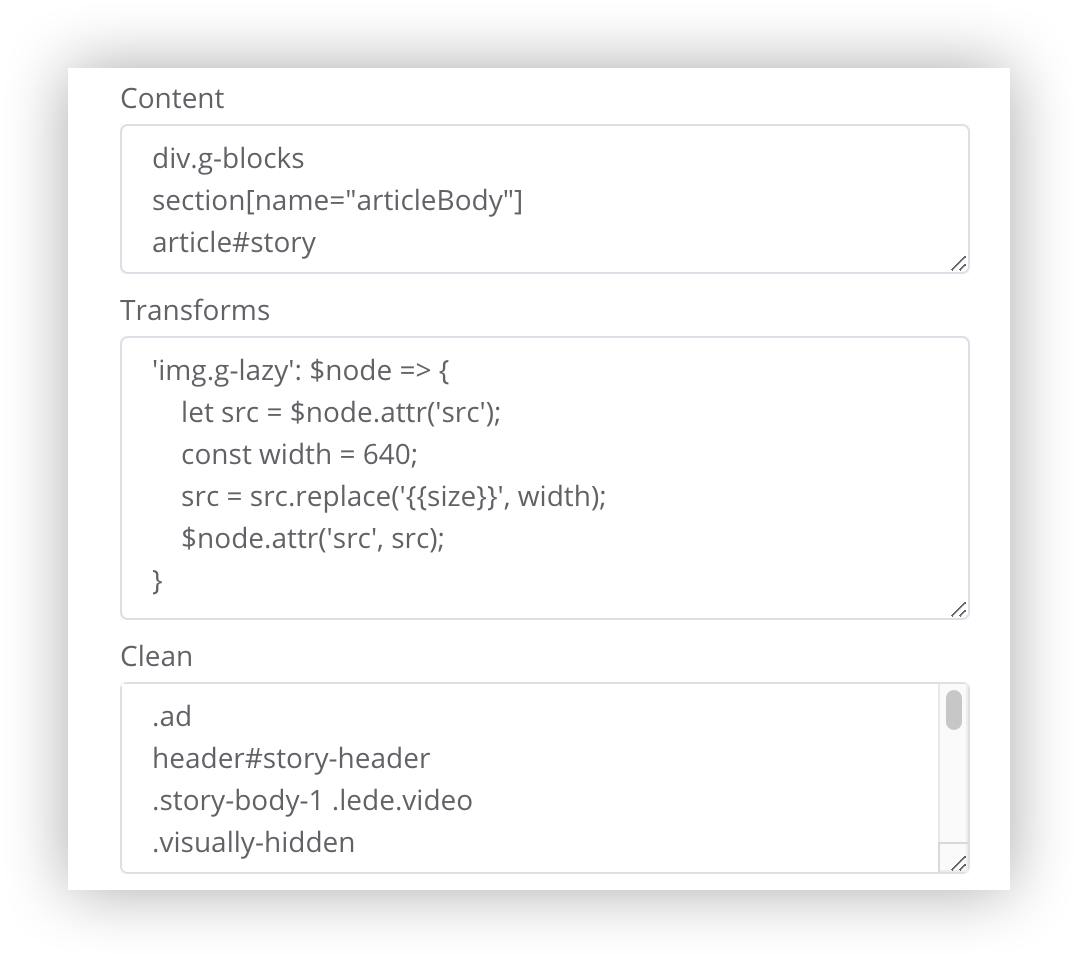
- Content - several selectors can be placed on one line and if all match text from the page the selector will be used. The line must be enclosed in square brackets and the selectors separated by commas and enclosed in single quotes (ie. ['div.intro', 'div.body'] )
- Transforms - This is a complex field and requires knowledge of Javascript to use but allows a function to be used to modify selected HTML in the page. The $node parameter is treated as a jQuery object. If multiple selector/function pairs are required, they should be separated by commas
- Clean - any text that matches these selectors will be deleted. The matching happens on the whole page (not on the extracted content which is the default Mercury behaviour). If the ":content()" selector (ie. "div:content('Advertisement')" ) is used it will only remove the HTML tag nearest the matching text (as opposed to tags above it which also technically qualify as having the specified content).
Bottom of form
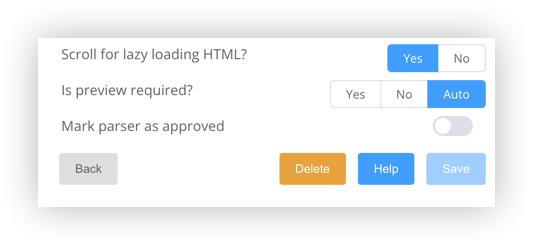
- Scroll for lazy loading HTML? - Some pages, especially very long ones, do not load all at once. Instead, they only load as the pages os scrolled down. Set this to "Yes" to ensure pages like these are fully captured. Setting it to "Yes" will never impede page capturing, it will only cause the screen to flash as it is scrolled.
- Is preview required - This three part button determines whether a preview image of the captured page will appear on the left side of the popup. If you are confident that the parser works consistently for a particular site, the "No" button can be selected which will speed up the clipping process. "Auto" will default to "Yes" unless a setting has been specified in the parser file definition (which only exists for complex parsers developed by Kuloo)
- Mark parser as approved - when you press "Save" the article is saved either as "Draft" or "Approved". You will only have this option if you are an approver for the channel you are posting to.
- Delete - this button appears after an article has been clipped and while the preview is displayed. If content was not clipped properly or if the article is not satisfactory for whatever reason (ie. formatting. etc.), this button will delete the article. As it is being deleted, a popup will allow you to optionally request that the parser be created or adjusted. A description of the problem and a priority should be entered.
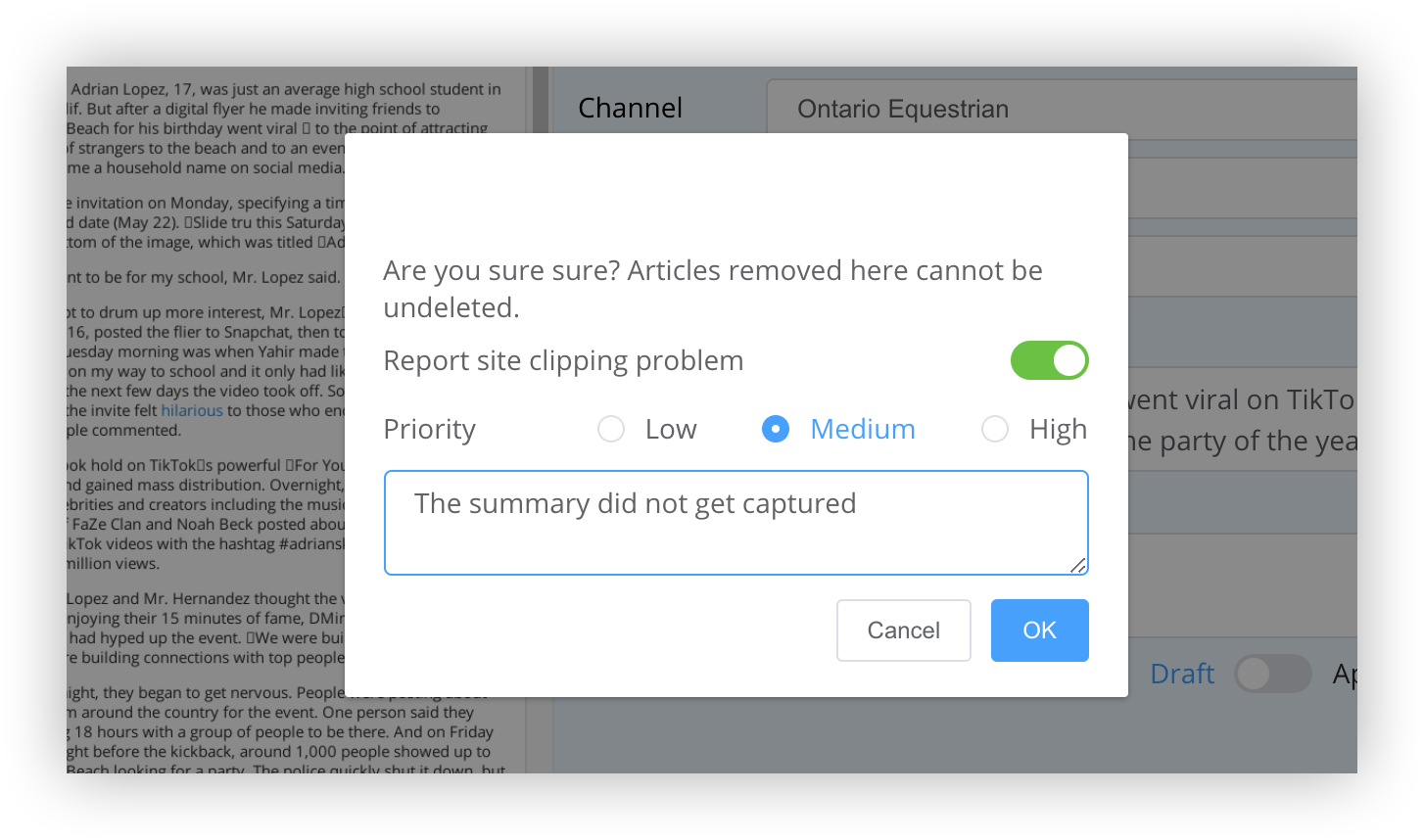
Depending on your account type and the number of requests for the site, the parser update will be prioritized and you will receive a notification when the update is completed. As well, the delete button can also be used to delete pages you have previously clipped. - Save - If you make any kind of a change on a parser, this button will be enabled to allow you to save your changes. If the current parser is already approved, a new version will be created in "draft" mode with the new changes.
Parser Fixed Notification
Once the parser definition has been approved, a notification will immediately go out to any user that requested a fix for that site. The notification appears as a green "FIXED" label on their original parser request notification.
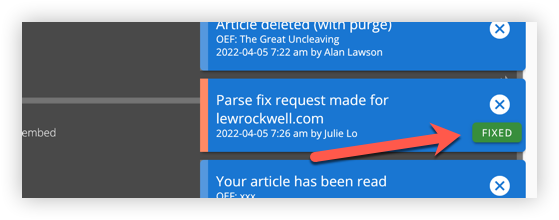
Tapping the notification will display the link that was involved in the original request. The user can try the page clipping once again with the updated parser settings.
Additional notes
- New parser definitions that have not been marked as "approved" will prevent others from creating or updating the parser for that site. This limitation expires after six hours without any modifications, allowing others to create new parser versions (the expired "draft" parser is automatically deleted).
- Keep in mind that the parser you create or modify will be used by all Kuloo users clipping pages from that site.
Comments
0 comments
Please sign in to leave a comment.